Introduction
The GAUSS dataframe, introduced in GAUSS 21, is a powerful tool for storing data. In today's blog, we explain what a GAUSS dataframe is and discuss the advantages of making it a part of your everyday GAUSS use.
What is a GAUSS dataframe?
The GAUSS dataframe is a tool for storing two-dimensional data. The dataframe allows you to store:
- Data in rows and columns, similar to the GAUSS matrix.
- Metadata about the data type and type-related properties.
- Different data types together in one place.
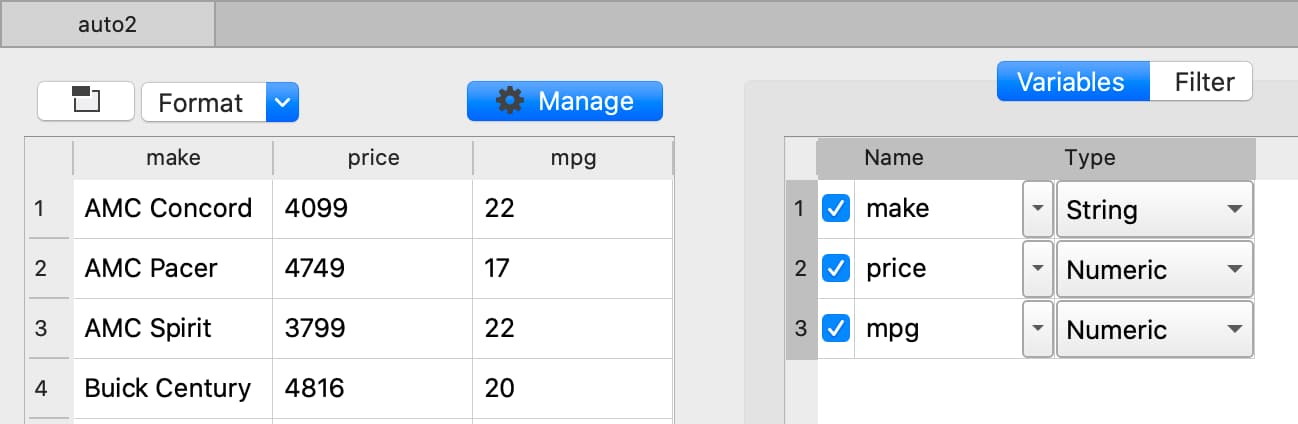
GAUSS dataframes keep your data together and familiar. They offer a number of advantages including:
- Intuitive display and management of strings, dates, and categorical data.
- Easy to read results and output.
- Simple data referencing with variable names and labels.
How do I create a GAUSS dataframe?
Creating a GAUSS dataframe is easy to do and often does not require extra steps. Let's look at a few different cases of dataframe creation.
Loading data interactively
The GAUSS Data Import window allows us to interactively import data from:
- CSV and other text delimited files.
- Excel files (XLS, XLSX).
- GAUSS datasets (DAT) and matrix files (FMT).
- SAS, Stata and SPSS datasets.
When loading data interactively, the Import Options tab lets you specify various aspects of data import, including the option to Keep Metadata:
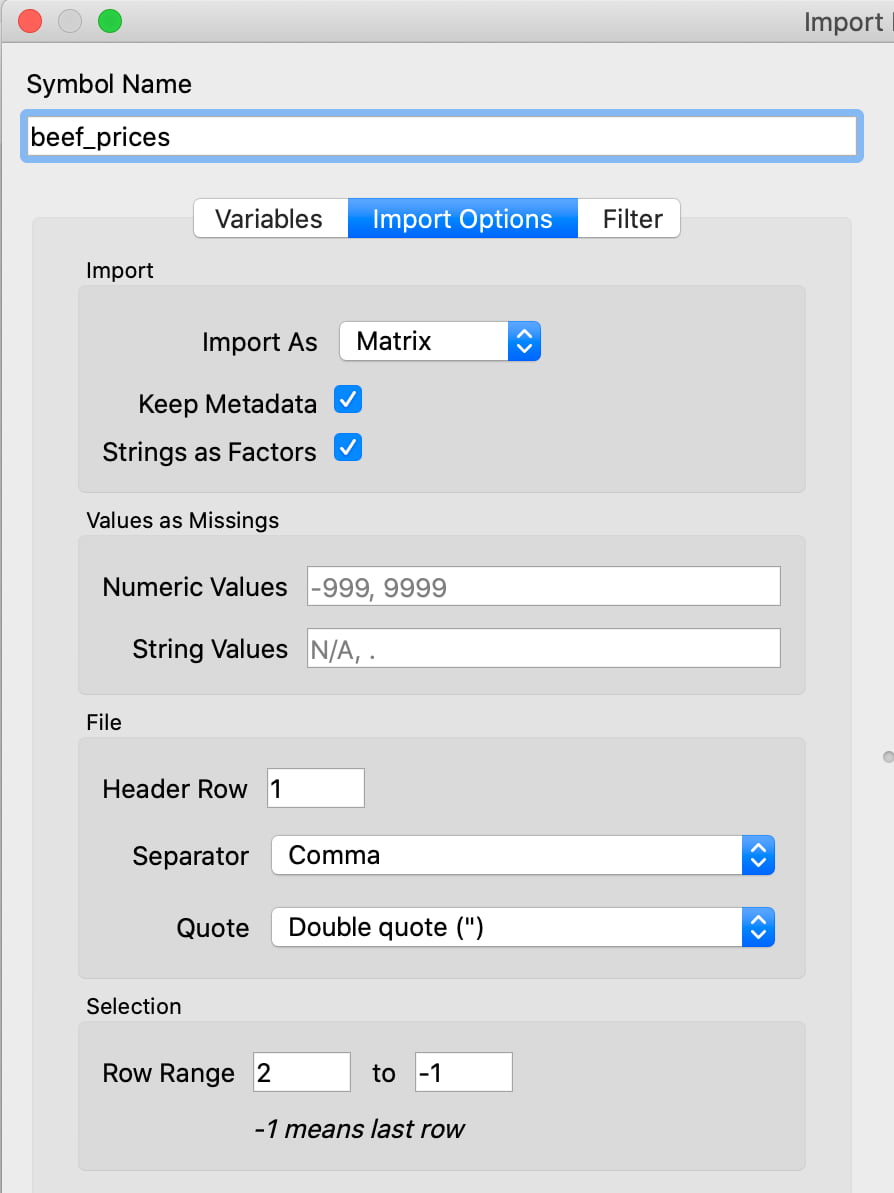
When Keep Metadata is checked:
- The data will be imported as a dataframe.
- Variable names, column types, and associated properties will be stored.
- Internal algorithms are used to determine variable types and the associated properties.
Programmatically loading a dataframe
// Create file name with full path
dataset = getGAUSSHome() $+ "examples/housing.csv";
// Load all variables from the file
housing = loadd(dataset);Creating a GAUSS dataframe programmatically is also very simple and is done by default when using the loadd function.
For datasets that do not have variable type information, such as XLS/XLSX and CSV files, key words are used to tell GAUSS how to interpret the columns:
| Keyword | Data Type | Example |
|---|---|---|
cat | Category | yarn = loadd(dataset, "cat(amplitude) + cycles") |
date | Date | eur_usd = loadd(dataset, "date(date) + bid + ask") |
str | String | nba = loadd(dataset, "str(player) + height + weight") |
Changing a GAUSS matrix to a dataframe
A GAUSS matrix can be changed to a dataframe using a number of functions designed for assigning metadata to a matrix. Any time metadata is assigned to a matrix, the matrix is converted into a dataframe.
For example, the setColMetaData function allows us to assign a variable name and type to a column.
x_dataframe = setColMetadata(X, varnames, types);- X
- N x K data matrix.
- varnames
- K x 1 string array, variable names to assign to columns.
- types
- Kx1 vector, Specifies types to be assigned to names in varnames. Valid options include 0: string, 1: number, 2: categorical 3: date.
| Function | Purpose |
|---|---|
setColMetadata | Set columns in a matrix to have variable names and types. |
setColNames | Set column variable names. |
setColTypes | Set column types. |
setColLabels | Set categorical labels for a column. |
What are the Data Types used in Dataframes?
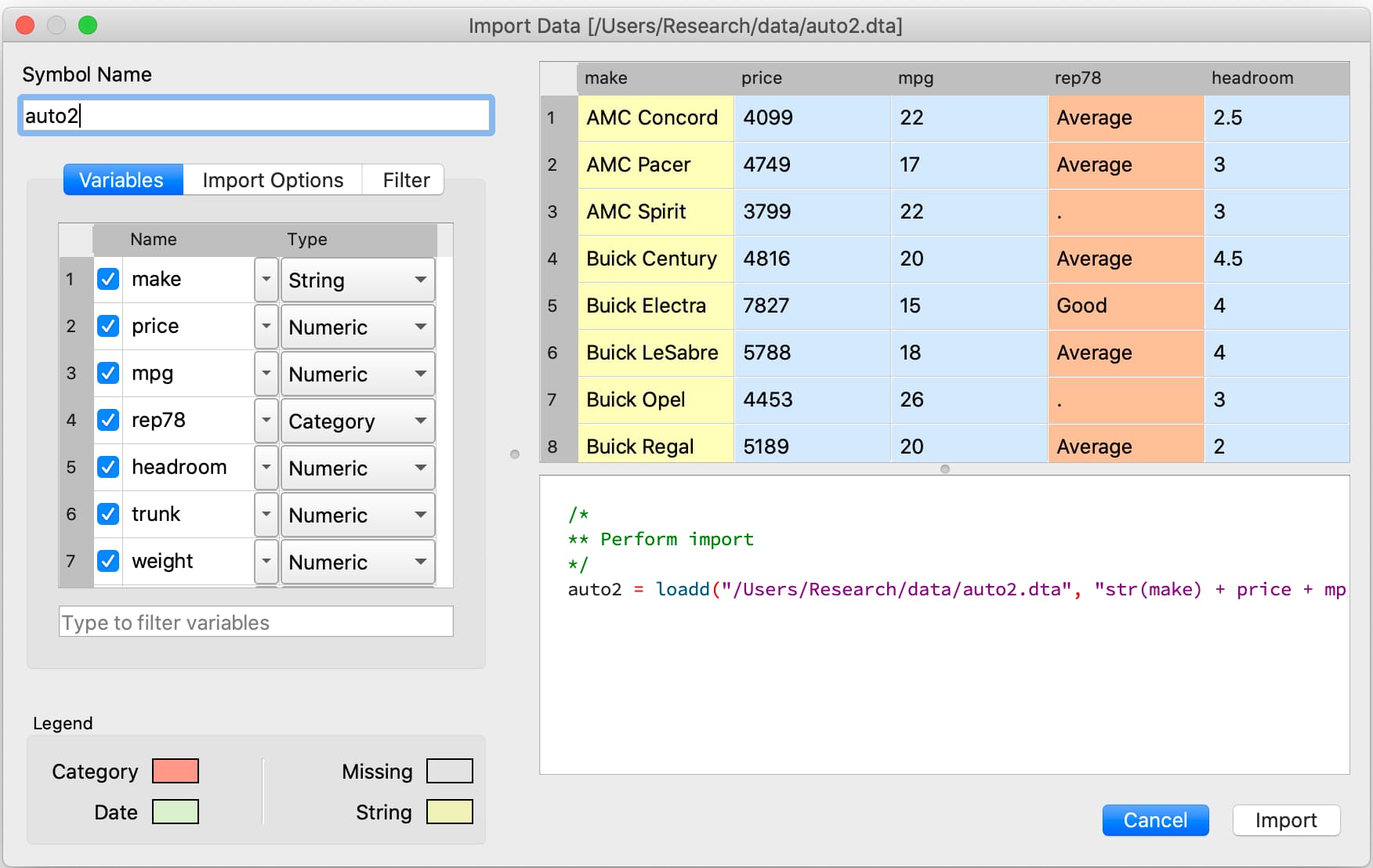 The GAUSS dataframes allow you to work with 4 different data types:
The GAUSS dataframes allow you to work with 4 different data types:
- Numeric
- Category
- String
- Date
The GAUSS Numeric data type
The Numeric data type is directly analogous to the data stored in a standard GAUSS matrix. The Numeric data type:
- Houses continuous numeric data.
- Can be directly used in all GAUSS functions that accept data matrices.
- Examples: Daily temperatures, real GDP, weight.
The GAUSS Category data type
The Category data type houses discrete variables that capture qualitative outcomes stored in fixed groups (or levels). The Category data type:
- Stores categorical labels and underlying key values.
- Can be directly used in a number of GAUSS functions with automatic dummy variable creation for estimation.
- Seamlessly integrates with categorical data in SAS/Stata/SPSS data files.
- Examples: Marriage status, performance ratings, weight class
The GAUSS String data type
The String data type can contain letters, numbers, and other characters. The String data type:
- Keeps labels with data.
- Saves additional loading steps.
- Makes data and reports easier to understand.
- Examples: Customer names, product name, location
The GAUSS Date type
The Date data type houses and displays dates and times. The Date data type:
- Saves time, frustration and errors when working with dates and times.
- Allows you to display dates in readable formats.
- Improves labeling in graphics.
Using Metadata
The information stored in GAUSS dataframes can easily be used to simplify data management, cleaning, and accessing, along with estimation.
Reference your data by name
One of the advantages of the GAUSS dataframe is that:
- Variables names.
- Categorical and string labels.
- Dates.
can be used to reference your data. This makes programming in GAUSS more intuitive and readable.
For example, suppose we want to extract just the mpg and rep78 variable from the auto dataframe. These can be indexed directly using variable names:
// Index by variable name
auto = auto[., "mpg" "rep78"];We can use the category label "C" to filter the data in our dataframe, NBA by the variable Pos:
// Select if position is center
nba = selif(nba, nba[., "Pos"] .$== "C");We can also filter dataframes using an easy-to-read date string.
// Select observations on or after June 20th, 2017
xle = selif(xle, xle[.,"date"] .>= "2017-06-20")Enhanced data exploration
Dataframes also improve data exploration with detailed, readable reports.
For example, when viewed in the Data Editor or printed to screen, a dataframe:
- Is readable and clear.
- Can be easily filtered and navigated using variable names, dates, etc.
- Keeps all your data in one place
>> print lending[1:5,.]; int_rate date purpose
12.620000 2014-12-14 credit_card
9.4400000 2014-05-18 auto
10.420000 2014-02-01 medical
15.050000 2014-04-05 credit_card
9.9300000 2014-05-17 credit_card
>> print lending[1:5,"purpose"]; purpose
credit_card
auto
medical
credit_card
credit_card
Summary statistics are more insightful with clearer tables.
>> dstatmt(auto2);--------------------------------------------------------------------------------------------- Variable Mean Std Dev Variance Minimum Maximum Valid Missing --------------------------------------------------------------------------------------------- make ----- ----- ----- ----- ----- 74 0 price 6165 2949 8.7e+06 3291 1.591e+04 74 0 mpg 21.3 5.786 33.47 12 41 74 0 rep78 ----- ----- ----- Poor Excellent 69 5 headroom 2.993 0.846 0.7157 1.5 5 74 0 trunk 13.76 4.277 18.3 5 23 74 0 weight 3019 777.2 604030 1760 4840 74 0 length 187.9 22.27 495.8 142 233 74 0 turn 39.65 4.399 19.35 31 51 74 0 displacement 197.3 91.84 8434 79 425 74 0 gear_ratio 3.015 0.4563 0.2082 2.19 3.89 74 0 foreign ----- ----- ----- Domestic Foreign 74 0
Using metadata in estimation
GAUSS dataframes makes estimation easy to implement and easy to interpret with no additional steps needed. GAUSS internally accesses metadata to use variable names, category labels, and dates when appropriate.
For example, if we include a categorical variable, like purpose from the dataset lending.csv dataset, GAUSS automatically:
- Creates the dummy variables needed for estimation.
- Excludes the base case.
- Includes category labels in the output table.
// Load data
lending = loadd("lending.csv");
// Estimate in one line
call olsmt(lending, "int_rate ~ ."); Std.
Variable Estimate Error t-value
-----------------------------------------------------------
CONSTANT 11.988 1.298 9.235
term: 60_months 3.987 0.6446 6.184
annual_inc -0.0092475 0.005473 -1.689
purpose: credit_card -0.12827 1.320 -0.09714
renewable_energy -1.9637 4.229 -0.4643
small_business 3.9262 1.799 2.182
vacation -0.7038 1.809 -0.3890
Want to see these advantages for yourself? Contact us for a GAUSS 21 demo!
Conclusion
The GAUSS dataframe is a powerful new data storage tool that offers many advantages. Whether you're just getting started with data exploration or you're in the final stages of estimation, you'll find that dataframes make your work easier and more intuitive.
Further reading
- Easy Management of Categorical Variables
- Preparing and Cleaning FRED data in GAUSS 21
- Easy and Fast Data Management in GAUSS 21
- Dates and Times Made Easy

Eric has been working to build, distribute, and strengthen the GAUSS universe since 2012. He is an economist skilled in data analysis and software development. He has earned a B.A. and MSc in economics and engineering and has over 18 years of combined industry and academic experience in data analysis and research.