Introduction
Our goal for this post is to learn the fundamentals of creating and using procedures in GAUSS. When you are finished, you should be able to create GAUSS procedures and use those written by others.
What is a GAUSS Procedure?
GAUSS procedures are user-defined functions. They allow you to combine a sequence of commands to perform a desired task.
A function is a block of organized, reusable code that is used to perform a single, related action. - Tutorialspoint.com
Why Create GAUSS Procedures?
There are many advantages to creating GAUSS procedures. Even if you don’t consider yourself a programmer, creating GAUSS procedures will make your work easier and more productive.
Save time. Every time you use a previously written GAUSS procedure you,
- Avoid rewriting the same code.
- Avoid debugging new or old mistakes.
- Keep your main code simpler and more readable.
How to Create a GAUSS Procedure Definition
Let’s start with a simple example. We’ll create a simple procedure named power which takes two inputs and returns one output.
proc (1) = power(X, p); // 1. Procedure declaration
local X_out; // 2. Local variable list
X_out = X ^ p; // 3. Procedure body
retp(X_out); // 4. Procedure return
endp; // 5. Procedure endEach line in the above procedure is one of the main parts of a GAUSS procedure. Now let's discuss the details of each of these elements.
1. The Procedure Declaration
a. c.
↓ ↓
proc (1) = power(X, p);
↑ ↑
b. d.The procedure declaration is the first line of all GAUSS procedures. It contains four main sections:
| Description | ||
|---|---|---|
| a. | proc |
Keyword that starts the procedure declaration. |
| b. | (1) = |
The number of items (matrices, strings, etc) that will be returned by this procedure. It is optional with a default value of 1. |
| c. | power |
The name of the procedure. |
| d. | (X,p) |
The required input arguments. |
Don't forget the ending semi-colon.
2. The Local Variable List
local X_out; The local variable list is a comma-separated list of variables that will be used inside the procedure. These local variables only exist when the procedure is running.
3. The Procedure Body
X_out = X ^ p;The procedure body is where the procedure's computations are performed. In this case, we have just one simple line. However, there is no limit to the size of your procedure.
You can use procedures created by you or others as well as any built-in GAUSS function or operator inside the body of your procedure.
4. The Procedure Return
retp(X_out);You can return any of the local variables from the procedure, or none at all. When returning more than one variable, use commas to separate the variable names.
5. The Procedure End
endp;The endp keyword signals the end of the procedure.
How to Use a GAUSS Procedure
There are two steps required to use a GAUSS procedure:
- Define the procedure.
- Call the procedure.
How to Define a GAUSS Procedure
When GAUSS first starts up, it is only aware of its own built-in functions and procedures. Defining a procedure is the process of making GAUSS aware of your procedure. If you try to use a procedure before it is defined, like this:
// Clear all data and procedures from the GAUSS workspace
new;
// Call procedure that has not been defined
power(3, 2);you will get the error G0025 : Undefined symbol: 'power'.
Here are four ways to define your GAUSS procedure:
- Add the procedure to your main code file.
- Run the GAUSS procedure.
- Place the procedure in a
.gfile. - Add your procedure to a GAUSS library.
1. Add the procedure to your main code file. The simplest method to define a procedure is to simply add it to your code and run the main file. This allows for a natural process of learning-by-doing.
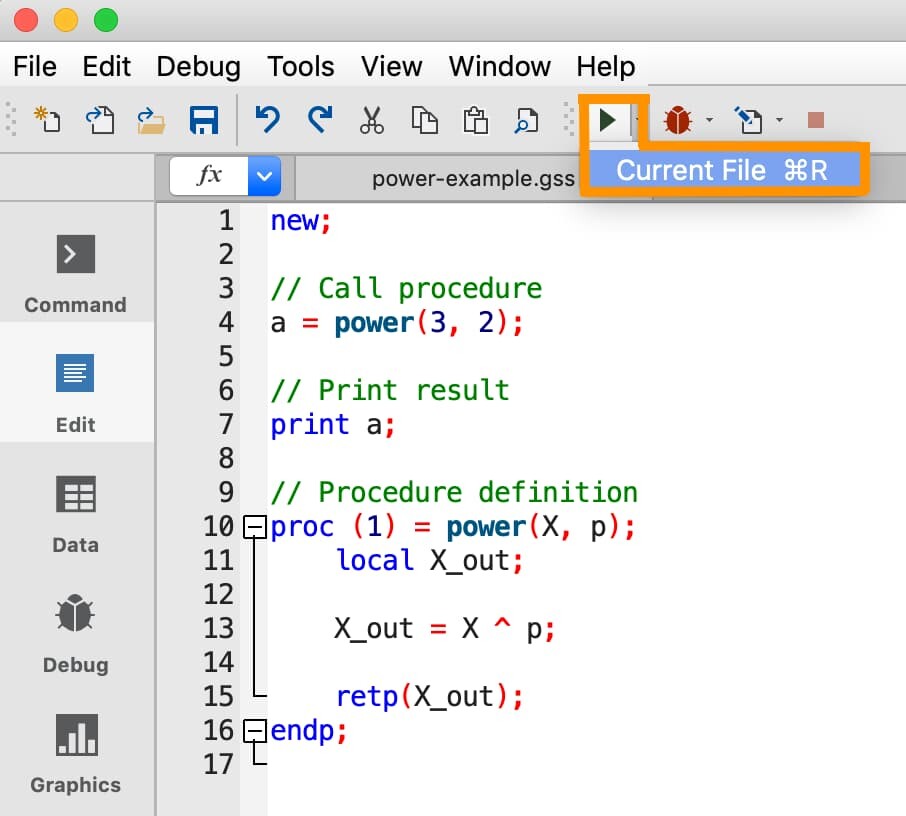
As we can see from the above image, the procedure can be included anywhere in your program file. It is often convenient to place procedures after the main code.
GAUSS can allow this because it does not just run your code line-by-line. It is smarter than that. When GAUSS runs your program, its first step is to compile your code. This allows GAUSS to find many mistakes immediately and also speed-up your code in addition to locating your procedures.
2. Run the GAUSS procedure. Since GAUSS does not run your code line-by-line, as we saw in the previous section, GAUSS needs to have the entire procedure definition at once. Therefore, you cannot run a procedure one line at a time. If you try to run the first line alone:
proc (1) = power(X, p);you will get the error G0278 : PROC without ENDP 'power'.
After you run the entire procedure:

the procedure is defined so that you can use it in GAUSS. Now running:
x = power(3, 2);
print x;will be successful, returning:
9
3. Place your procedure in a .g file. It is not always convenient to keep all procedures in your main code file.
A simple alternative is to:
i. Create a file with the same name as your procedure plus a .g file extension. Such as power.g.
ii. Place your procedure in this file.
iii. Save this file in a location where GAUSS can find it.
4. Add your procedure to a GAUSS library. Adding your related procedures to a GAUSS library is considered a best practice. GAUSS libraries make it easier to use and share code without worrying about paths.

Full GAUSS library management is beyond the scope of this article. However, the above image shows the Create Library and Add Files controls.
How to Call a GAUSS Procedure
Now that we've learned how to create and define GAUSS procedures, it's time to use them. Here are a few example procedures to fill in anything you might be unsure about.
We'll start with a procedure with two returns.
// Create 4x1 vector
y = { 1, 3, 2, 1 };
// Call procedure
{ a, b } = range(y);
// Print results
print "The smallest value is: " a;
print "The largest value is : " b;
// Procedure that returns two items
proc (2) = range(X);
local min, max;
min = minc(X);
max = maxc(X);
retp(min, max);
endp;Running the above code will return:
The smallest value is: 1 The largest value is : 3
Next, we'll consider a case with two inputs.
// Create 5x1 vector
z = { 1, 2, 3, 4, 9 };
m1 = average(z, "median");
print m1;
m2 = average(z, "mean");
print m2;
proc (1) = average(y, type_);
local avg;
if type_ $== "mean";
avg = meanc(y);
elseif type_ $== "median";
avg = median(y);
else;
print "Second input, type_, not recognized";
end;
endif;
retp(avg);
endp;which will return:
3.0 3.8
Conclusion
Great job! You've made it through the fundamentals of GAUSS procedures. You've learned:
- The parts that make up a GAUSS procedure.
- How to define GAUSS procedures.
- How to call GAUSS procedures.
I am trying to use carrion-i-silvestre panel data unit root in which pdWide is use. This command is not found in the gauss programe. please help me